Short description
Locust is a load testing tool. You describe simulated users in a small Python file, then watch how your service behaves as concurrency rises.
Purpose and how people use it
People use Locust to find where a service slows down or breaks under load. For an AI stack it answers a specific question: how many simultaneous requests can my model endpoint handle before latency climbs. It pairs well with a gateway, since you can load test the single endpoint that fronts everything.
Prerequisites
- Python 3 with the venv module. On Debian or Ubuntu you may need to install it first with
sudo apt install python3-venv. - A running endpoint to test, for example the LiteLLM gateway on port 4000.
Quick setup
mkdir -p ~/locust && cd ~/locust
python3 -m venv .venv
source .venv/bin/activate
pip install locustCreate a test file that hits an OpenAI compatible chat endpoint:
cat > locustfile.py << 'EOF'
import os
from locust import HttpUser, task, between
LITELLM_KEY = os.getenv("LITELLM_KEY", "sk-REPLACE-ME")
MODEL = os.getenv("MODEL", "qwen3-32b")
class LiteLLMUser(HttpUser):
wait_time = between(1, 3)
@task
def chat(self):
self.client.post(
"/v1/chat/completions",
headers={
"Authorization": f"Bearer {LITELLM_KEY}",
"Content-Type": "application/json",
},
json={
"model": MODEL,
"messages": [{"role": "user", "content": "Say hello in one short sentence."}],
"max_tokens": 50,
},
name="/v1/chat/completions",
)
EOFSet your key and run:
export LITELLM_KEY="sk-your-real-key"
export MODEL="qwen3-32b"
locust -f locustfile.py --host http://localhost:4000Open http://localhost:8089, set a small number of users (start with 5) and a spawn rate of 1, then press Start. Watch requests per second, the median and 95th percentile response times, and the failure rate.
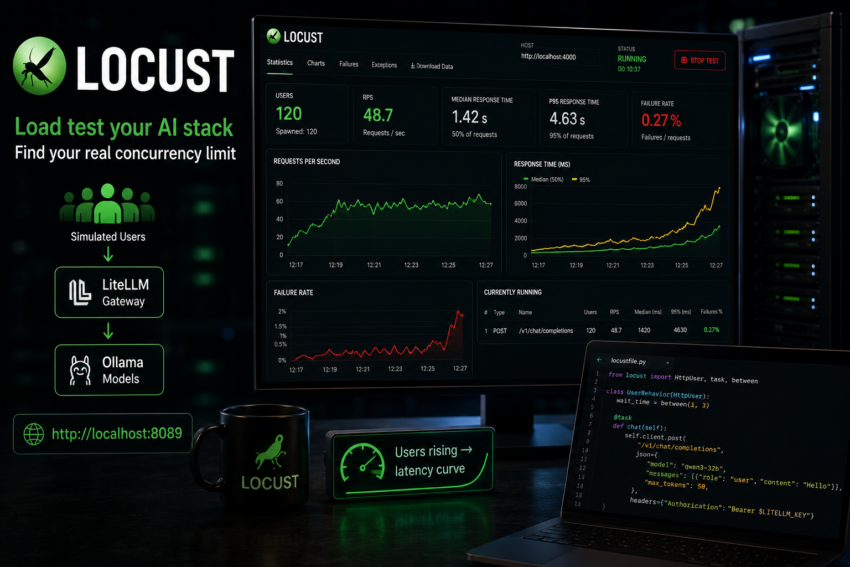
The one thing that trips everyone up
Locust here runs natively, not in a container, so the target host is http://localhost:4000, not host.docker.internal. Also remember that a local LLM is slow compared to a normal web app. The useful result is the saturation point: the user count where the median response time stops being flat and starts climbing. That bend is your real concurrency limit.
Reading the result
Do not chase a high requests per second number. With a single GPU, generation is the bottleneck, and concurrency is governed by how many requests the model server runs in parallel. The valuable output is the shape of the latency curve as users rise, not the peak throughput.